WPGraphQL makes use of cursor-based pagination, inspired by the Relay specification for GraphQL Connections. If you’re not familiar with cursor-based pagination it can be confusing to understand and implement in your applications.
In this post, we’ll compare cursor-based pagination to page-based pagination, and will look at how to implement forward and backward pagination in a React application using Apollo Client.
Before we dive into cursor-based pagination, let’s first look at one of the most common pagination techniques: Page-based pagination.
Page Based Pagination
Many applications you are likely familiar with paginate data using pages. For example, if you visit Google on your desktop and search for something and scroll down to the bottom of the page, you will see page numbers allowing you to paginate through the data.

WordPress also has page-based pagination mechanisms built-in. For example, within the WordPress dashboard your Posts are paginated:
And many WordPress themes, such as the default TwentyTwenty theme feature page-based pagination:

How Page-Based Pagination Works
Page-based pagination works by calculating the total number of records matching a query and dividing the total by the number of results requested for each page. Requesting a specific page results in a database request that skips the number of records totaling the number of records per page multiplied by the number of pages to skip. For example, visiting page 9 on a site showing 10 records per page would ask the database to skip 90 records, and show records 91-100.
Performance Problems with Page-Based Pagination
If you’ve ever worked with on a WordPress site with a lot of records, you’ve likely run into performance issues and looked into how to make WordPress more performant. One of the first recommendations you’re likely to come across, is to not ask WordPress to calculate the total number of records. For example, the 10up Engineering Best Practices first recommendation is to set the WP_Query argument no_found_rows to true, which asks WordPress to not calculate the total records.
As the total number of records grow, the longer it takes for your database to execute this calculation. As you continue to publish posts, your site will continue to get slower.
In addition to calculating the total records, paginated requests also ask the database to skip a certain number of records, which also adds to the weight of the query. In our example above, visiting page 9 would ask the database to skip 90 records. In order for a database to skip these records, it has to first find them, which adds to the overall execution. If you were to ask for page 500, on a site paginated by 100 items per page, you would be asking the database to skip 50,000 records. This can take a while to execute. And while your everyday user might not want to visit page 500, some will. And search engines and crawlers will as well, and that can take a toll on your servers.
The (lack of) Value of Page Numbers in User Interfaces
As a user, what value do page numbers provide in terms of user experience?
For real. Think about it.
If you are on my blog, what does “page 5” mean to you?
What does “page 5” mean to you on a Google search results?
Sure, it means you will get items “50-60”, but what does that actually mean to you as a user?
You have no realistic expectation for what will be on that page. Page 5 on my blog might be posts from last week, if I blogged regularly, but Page 5 also might be blog posts from 2004. You, as the user don’t know what to expect when you click a page number. You’re just playing a guessing game.
It’s likely that if you clicked page 5 on my blog, you are looking for older content. Instead of playing a guessing game clicking arbitrary page numbers, it would make more sense and provide more value to the user if the UI provided a way to filter by date ranges. This way, if you’re looking for posts from yesterday, or from 2004, you could target that specifically, instead of arbitrarily clicking page numbers and hoping you find something relevant to what you’re looking for.
Inconsistent data in page-based UIs
Page based UIs aren’t consistent in the content they provide.
For example, if I have 20 blog posts, separated in 2 pages, page 1 would include posts 20-11 (most recently published posts), and page 2 would include posts 1-10. As soon as I publish another article, page 1 now would include items 21-12, page 2 would include items 2-11, and we’d have a page 3 with item 1, the oldest post.
Each time a new blog post is published, the content of each paginated archive page changes. What was on page 5 today, won’t be the same next time content is published.
This further promotes the fact that the value provided to users in page numbers is confusing. If the content on the pages remained constant, at least the user could find the content they were looking for by always visiting page 5, but that’s not the case. Page 5 might look completely different next time you click on it.
Cursor-Based Pagination
Many modern applications you’re likely familiar with use cursor-based pagination. Instead of dividing the total records into chunks and skipping records to paginate, cursor-based pagination loads the initial set of records and provides a cursor, or a reference point, for the next request to use to ask for the next set of records.
Some examples of this type of pagination in action would be loading more tweets as you scroll on Twitter, loading more posts as you scroll on Facebook, or loading more Slack messages as you scroll in a channel.
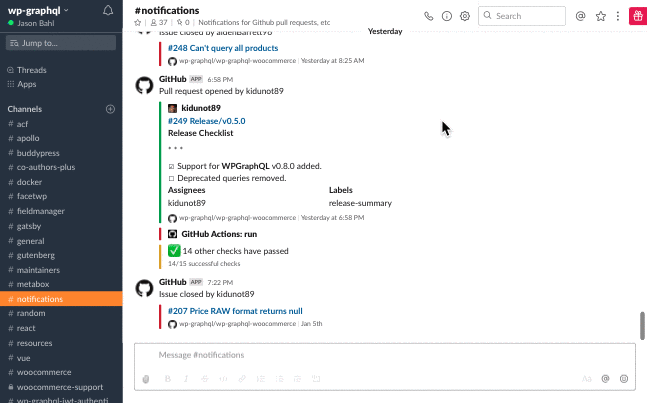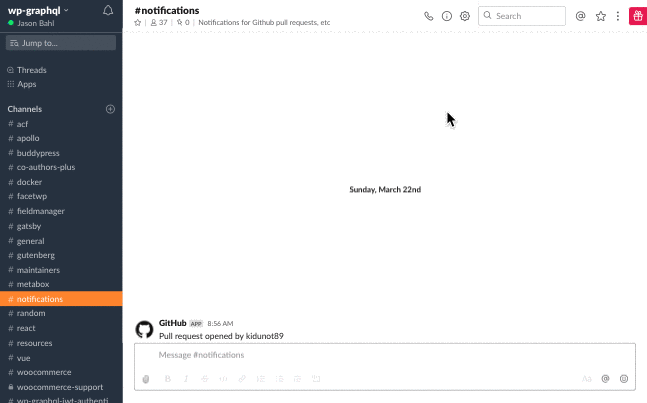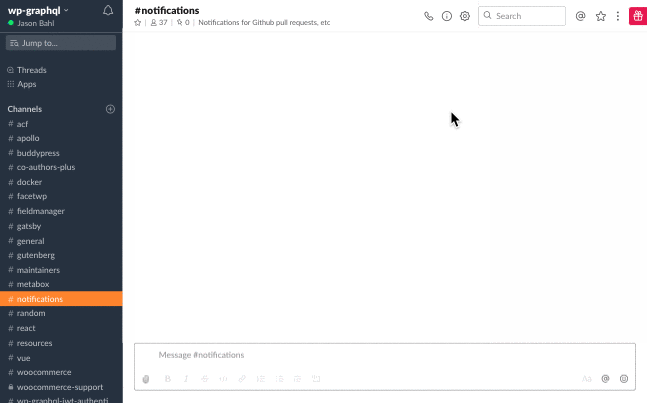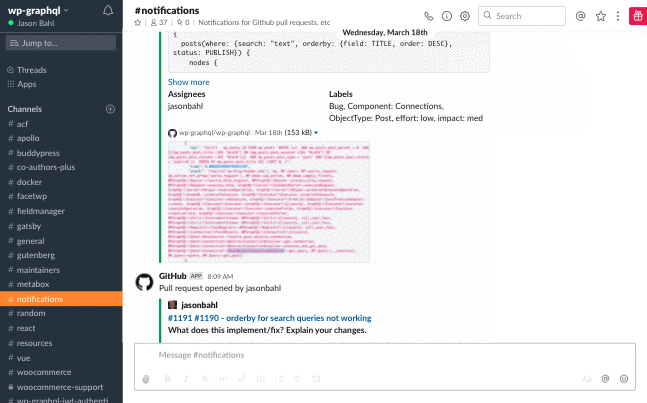
As you scroll up or down within a Slack channel, the next set of messages are loaded into view (often so fast that you don’t even notice). You don’t arbitrarily click page numbers to go backward or forward in the channel and view the next set of messages. When you first enter a channel, Slack loads an initial list of messages and as you scroll, it uses a cursor (a reference point) to ask the server for the next set of messages.
Michael Hahn, a Software Engineer at Slack wrote about how Slack uses cursor pagination.
In some cases, such as Slack channels, infinite scrolling for pagination can enhance the user experience. But in some cases, it can harm the user experience. The good news is that cursor-based pagination isn’t limited to being implemented via infinite scroll. You can implement cursor pagination using Next / Previous links, or a “Load More” link.
Google, for example, when used on mobile devices uses a “More results” button. This avoids subjecting users to the guessing game that page numbers lead to, and also avoids some of the downsides of infinite scrolling.
Performance of Cursor Based Pagination
Cursor pagination works by using the reference, the cursor, to point to a specific place in the dataset, and move forward or backward from that point. Page-based pagination needs to skip x amount of records, where cursor pagination can go directly to a point and start there. As you page through records with page-based pagination your queries get slower and slower, and it’s further impacted by the size of the dataset. With cursor pagination, the size of your dataset doesn’t affect performance. You are going to a specific point in the dataset and returning x number of records before or after that point. Going 500 pages deep will get quite slow on page-based, but will remain equally performant with cursor-based pagination.
No Skipped Data
Let’s say you visit your Facebook newsfeed. You immediately see 5 posts from your network of family and friends. Let’s say the data looks something like the following:
- COVID-19 update from Tim
- Meme from Jen
- Embarrassing Photo 1 from Mick
- Embarrassing Photo 2 from Mick
- Dog photo from Maddie
- Quarantine update from Stephanie
- Inspirational quote from Dave
- Breaking Bad meme from Eric
- Quarantine update from your local newspaper
- Work from Home tips from Chris
In page-based pagination, the data would look like so:
| Page 1 | Page 2 |
| COVID-19 update from Tim | Quarantine update from Stephanie |
| Meme from Jen | Inspirational quote from Dave |
| Embarrassing Photo 1 from Mick | Breaking Bad meme from Eric |
| Embarrassing Photo 2 from Mick | Quarantine update from your local newspaper |
| Dog photo from Maddie | Work from Home tips from Chris |
Let’s say Mick wakes up and realizes he shouldn’t have posted the embarrassing pics. He deletes the pics at the same time you’re looking at Page 1 of the posts.
When you scroll to look at more posts, the overall dataset now looks like the following:
| Page 1 | Page 2 |
| COVID-19 update from Tim | Breaking Bad meme from Eric |
| Meme from Jen | Quarantine update from your local newspaper |
| Dog photo from Maddie | Work from Home tips from Chris |
| Quarantine update from Stephanie | 5 Keto Recipes from Barb |
| Inspirational quote from Dave | “Tiger King” trailer from Cassie |
Since the two embarrassing photos were deleted, page 2 now looks different. Both “Quarantine update from Stephanie” and “Inspirational quote from Dave” are not on Page 2 anymore. They slid up to page 1. But the user already loaded page 1 which included the now deleted pice. So, when you scroll, and page 2 loads, these two posts won’t be included in your feed!
With page-based pagination, you would miss out on some content and not have any way to know that you missed it!
And Dave and Stephanie will be sad that you didn’t like their posts.
This happens because the underlying SQL query looks something like this:
SELECT * from wp_posts OFFSET 0, LIMIT 5 // Page 1, first 5 records SELECT * from wp_posts OFFSET 5, LIMIT 5 // Page 2, skips 5 records regardless
With cursor pagination, a pointer is sent back and used to query the next set of data. In this case, it might be a timestamp. So, when you scroll to load more posts, with cursor pagination you would get all items published after the last cursor. So, “Quarantine update from Stephanie” and “Inspirational quote from Dave” would be included because they were posted after the timestamp of the embarrassing photos that have been deleted. The cursor goes to a specific point in the dataset, and asks for the next set of records after that point.
The underlying SQL query for cursor pagination looks something like this:
SELECT * from wp_posts WHERE cursor > wp_posts.post_date ORDER BY wp_posts.post_date LIMIT 5
So, instead of skipping 5 records, we just get the next set of posts based on publish date (or whatever the query is being ordered by). This ensures that the user is getting the proper data, even if there have been changes to the existing dataset.
Cursor Pagination with WPGraphQL
Below is an example of forward and backward pagination implemented in a React + Apollo application.
(If your browser isn’t loading this example application below, click here to open it in a new window)
In this example, we’ll focus specifically on the list.js file.
Paginated Query
One of the first things you will see is a paginated query.
query GET_PAGINATED_POSTS(
$first: Int
$last: Int
$after: String
$before: String
) {
posts(first: $first, last: $last, after: $after, before: $before) {
pageInfo {
hasNextPage
hasPreviousPage
startCursor
endCursor
}
edges {
cursor
node {
id
postId
title
}
}
}
}
In this query, we define the variables first, last, after and before. These are options that can be passed to the query to affect the behavior. For forward pagination first and after are used, and for backward pagination last and before are used.
In addition to asking for a list of posts, we also ask for pageInfo about the query. This is information that informs the client whether there are more records or not, and how to fetch them. If hasNextPage is true, we know we can paginate forward. If hasPreviousPage is true, we know we can paginate backwards.
Our PostList component makes use of the Apollo useQuery hook to make an initial query with the variables: { first: 10, after: null, last: null, before: null }. This will ask WPGraphQL for the first 10 posts, which will be the 10 most recently published posts.
When the data is returned, we map over the posts and return them and render the Post titles as unordered list items.
Next / Previous buttons
Since there are more than 10 posts, the pageInfo.hasNextPage value will be true, and when this value is true, we know we can safely show our Next button. Since this is the first page of data, there are no posts more recent, so pageInfo.hasPreviousPage will be false. Since this is false, we will not load the Previous Button.
The initial load of the application is a list of 10 posts with a Next button.

When the “Next” button is clicked, it makes use of the Apollo fetchMore method, and re-queries the same query, but changing the variables to: { first: 10, after: pageInfo.endCursor, last: null, before: null }. These variables tell WPGraphQL we want the first 10 posts after the endCursor, which is a reference to the last item in the list on the first page. When those posts are returned, we make use of Apollo’s updateQuery method to replace the Post list with the new list.
So now, after clicking “Next”, we have a new list of posts displayed, and both a “Previous” and “Next” button.
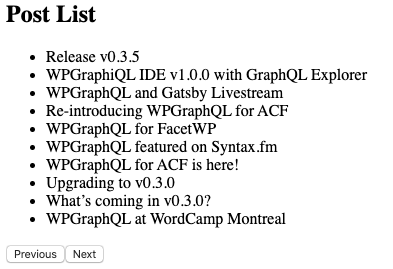
Both the Previous and Next buttons are displayed, because the values for pageInfo.hasNextPage and pageInfo.hasPreviousPage were both true. This information from the query tells the client that there are posts on either side, so we can paginate forward or backward.
If we click “Next” a few more times, we will reach the end of the dataset, and pageInfo.hasNextPage will be false, and we will no longer want to show the “Next” button.

When the “Previous” button is clicked, it makes use of the Apollo fetchMore method, and re-queries the same query, but changing the variables to: { first: null, after: null, last: 10, before: pageInfo.startCursor }. These variables tell WPGraphQL we want the last 10 posts before the startCursor, which is a reference to the first item in the list on the page. This allows us to paginate backward and get the previous items. When those previous posts are returned, we make use of Apollo’s updateQuery method to replace the Post list with the new list, and we’re back to showing both “Previous” and “Next” buttons again, until you click previous enough times to be back at the beginning of the dataset.
Summary
In this post, I compared page-based pagination and cursor-based pagination. We then looked at an example application built with React and Apollo querying the WPGraphQL.com GraphQL API and implementing forward and backward pagination.
I hope this article helps inspire you to use WPGraphQL in fun ways as we build the future of the web together!
Leave a Reply