One of the most common ways WordPress is used, is by users visiting a URL of a WordPress site and reading the content on the page.
WordPress has internal mechanisms that take the url from the request, determine what type of entity the user is requesting (a page, a blog post, a taxonomy term archive, an author’s page, etc) and then returns a specific template for that type of content.
This is a convention that users experience daily on the web, and something developers use to deliver unique experiences for their website users.
When you go “headless” with WordPress, and use something other than WordPress’s native theme layer to display the content, it can be tricky to determine how to take a url provided by a user and convert that into content to show your users.
In this post, we’ll take a look at a powerful feature of WPGraphQL, the nodeByUri query, which accepts a uri input (the path to the resource) and will return the node (the WordPress entity) in response.
You can use this to re-create the same experience WordPress theme layer provides, by returning unique templates based on the type of content being requested.
WPGraphQL’s “nodeByUri” query
One of the benefits of GraphQL is that it can provide entry points into the “graph” that (using Interfaces or Unions) can return different Types of data from one field.
WPGraphQL provides a field at the root of the graph named nodeByUri. This field accepts one argument as input, a $uri. And it returns a node, of any Type that has a uri. This means any public entity in WordPress, such as published authors, archive pages, posts of a public post type, terms of a public taxonomy, etc.
When a URI is input, this field resolves to the “node” (post, page, etc) that is associated with the URI, much like entering the URI in a web browser would resolve to that piece of content.
If you’ve not already used the “nodeByUri” query, it might be difficult to understand just reading about it, so let’s take a look at this in action.
Here’s a video where I walk through it, and below are some highlights of what I show in the video.
Writing the query
Let’s start by querying the homepage.
First, we’ll write our query:
query GetNodeByUri($uri: String!) {
nodeByUri(uri: $uri) {
__typename
}
}In this query, we’re doing a few things.
First, we give our query a name “GetNodeByUri”. This name can be anything we want, but it can be helpful with tooling, so it’s best practice to give your queries good names.
Next, we define our variable input to accept: $uri: String!. This tells GraphQL that there will be one input that we don’t know about up front, but we agree that we will submit the input as a string.
Next, we declare what field we want to access in the graph: nodeByUri( uri: $uri ). We’re telling WPGraphQL that we want to give it a URI, and in response, we want a node back.
The nodeByUri field is defined in the Schema to return the GraphQL Type UniformResourceIdentifiable, which is a GraphQL Interface implemented by any Type in the Graph that can be accessed via a public uri.
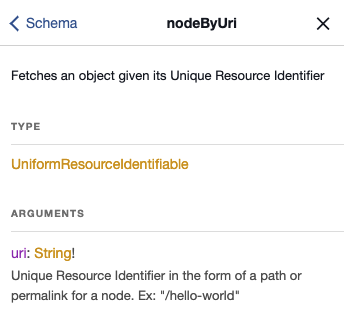
nodeByUri field shown in GraphiQLIf we inspect the documentation in GraphiQL for this type, we can see all of the available Types that can be returned.
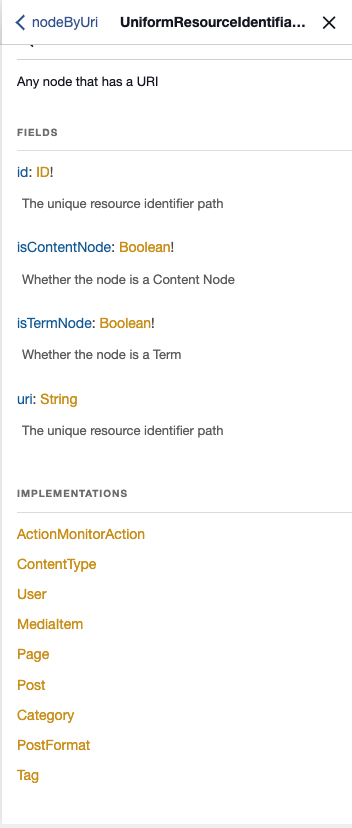
The Types that can be returned consist of public Post Types, Public Taxonomies, ContentType (archives), MediaItem, and User (published authors are public).
So, we know that any uri (path) that we query, we know what we can ask for and what to expect in response.
Execute the query
Now that we have the query written, we can use GraphiQL to execute the query.
GraphiQL has a “variables” pane that we will use to input our variables. In this case, the “uri” (or path) to the resource is our variable.
First, we will enter “/” as our uri value so we can test querying the home page.
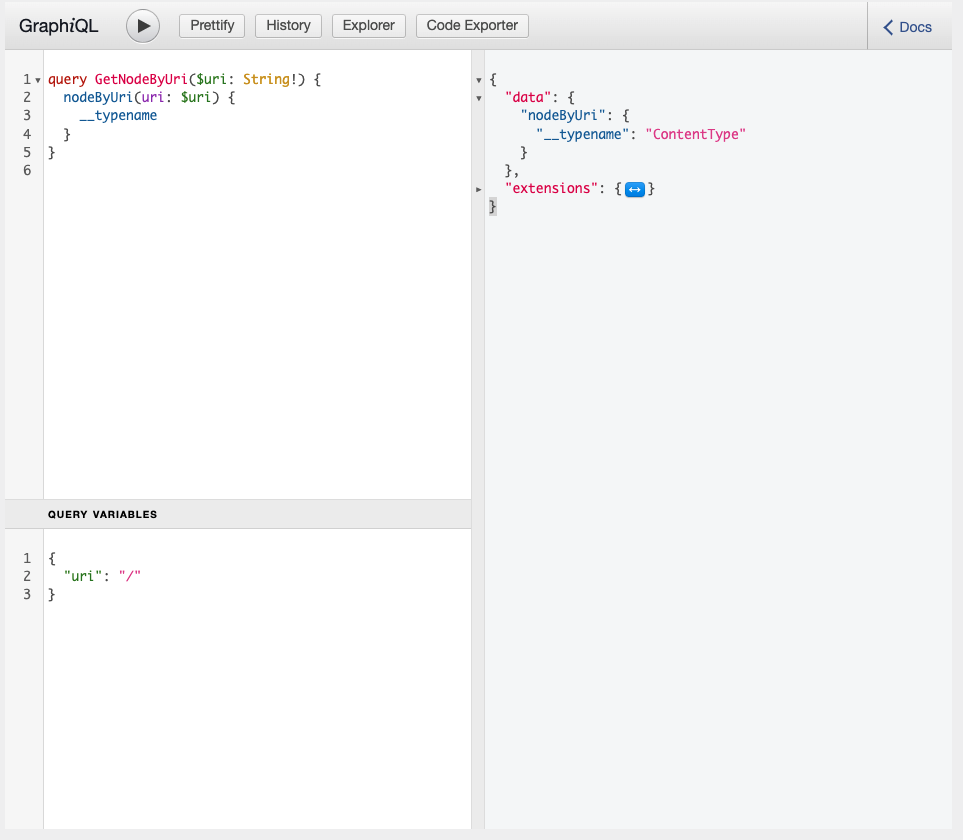
Now, we can execute our query by pressing the “Play” button in GraphiQL.
And in response we should see the following response:
{
"data": {
"nodeByUri": {
"__typename": "ContentType"
}
}
}
Expanding the query
We can see that when we query for the home page, we’re getting a “ContentType” node in response.
We can expand the query to ask for more fields of the “ContentType”.
If we look at the home page of https://demo.wpgraphql.com, we will see that it serves as the “blogroll” or the blog index. It’s a list of blog posts.
This is why WPGraphQL returns a “ContentType” node from the Graph.
We can write a fragment on this Type to ask for fields we want when the query returns a “ContentType” node.
If we look at the documentation in GraphiQL for the ContentType type, we can see all the fields that we can ask for.
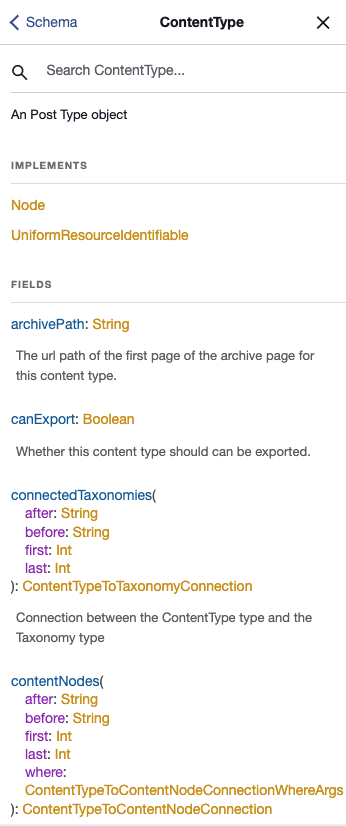
If our goal is to re-create the homepage we’re seeing in WordPress, then we certainly don’t need all the fields! We can specify exactly what we need.
In this case, we want to ask for the following fields:
- name: the name of the content type
- isFrontPage: whether the contentType should be considered the front page
- contentNodes (and sub-fields): a connection to the contentNodes on the page
This should give us enough information to re-create what we’re seeing on the homepage.
Let’s update our query to the following:
query GetNodeByUri($uri: String!) {
nodeByUri(uri: $uri) {
__typename
... on ContentType {
name
uri
isFrontPage
contentNodes {
nodes {
__typename
... on Post {
id
title
}
}
}
}
}
}
And then execute the query again.
We now see the following results:
{
"data": {
"nodeByUri": {
"__typename": "ContentType",
"name": "post",
"uri": "/",
"isFrontPage": true,
"contentNodes": {
"nodes": [
{
"__typename": "Post",
"id": "cG9zdDoxMDMx",
"title": "Tiled Gallery"
},
{
"__typename": "Post",
"id": "cG9zdDoxMDI3",
"title": "Twitter Embeds"
},
{
"__typename": "Post",
"id": "cG9zdDoxMDE2",
"title": "Featured Image (Vertical)…yo"
},
{
"__typename": "Post",
"id": "cG9zdDoxMDEx",
"title": "Featured Image (Horizontal)…yo"
},
{
"__typename": "Post",
"id": "cG9zdDoxMDAw",
"title": "Nested And Mixed Lists"
},
{
"__typename": "Post",
"id": "cG9zdDo5OTY=",
"title": "More Tag"
},
{
"__typename": "Post",
"id": "cG9zdDo5OTM=",
"title": "Excerpt"
},
{
"__typename": "Post",
"id": "cG9zdDo5MTk=",
"title": "Markup And Formatting"
},
{
"__typename": "Post",
"id": "cG9zdDo5MDM=",
"title": "Image Alignment"
},
{
"__typename": "Post",
"id": "cG9zdDo4OTU=",
"title": "Text Alignment"
}
]
}
}
}
}If we compare these results from our GraphQL Query, we can see that we’re starting to get data that matches the homepage that WordPress is rendering.
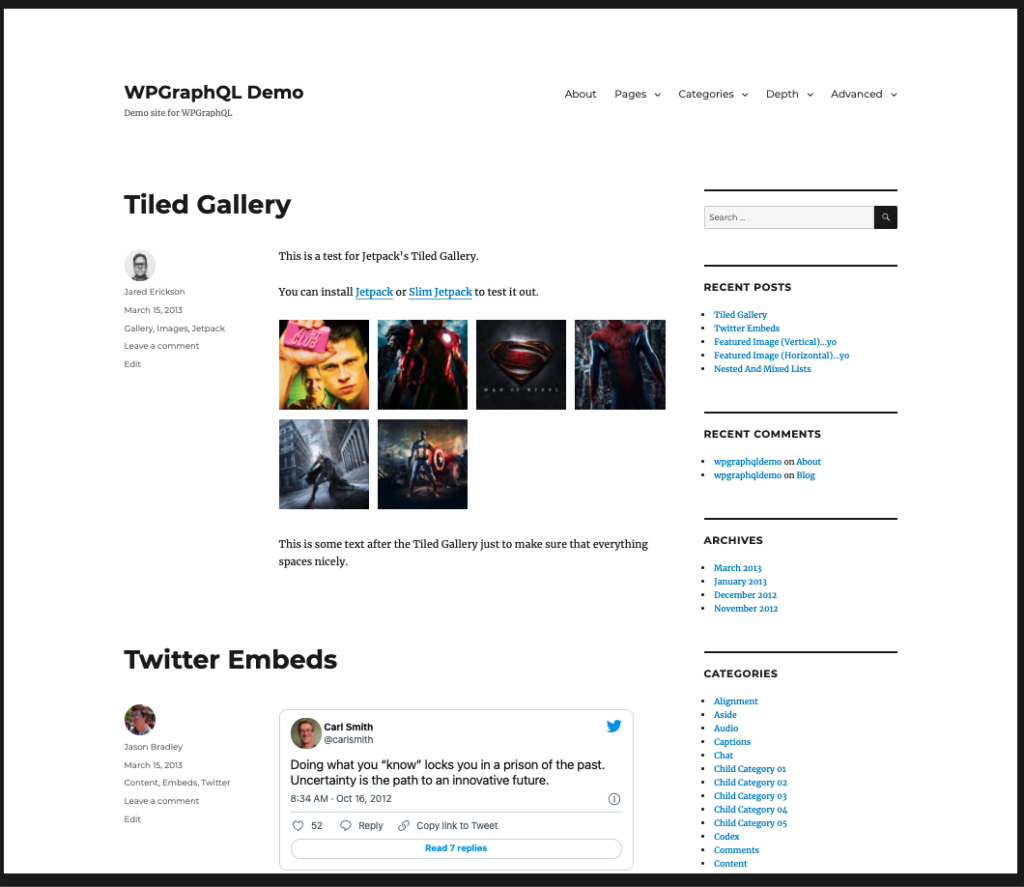
There’s more information on each post, such as:
- post author
- name
- avatar url
- post date
- post content
- uri (to link to the post with)
We can update our query once more with this additional information.
query GetNodeByUri($uri: String!) {
nodeByUri(uri: $uri) {
__typename
... on ContentType {
name
uri
isFrontPage
contentNodes {
nodes {
__typename
... on Post {
id
title
author {
node {
name
avatar {
url
}
}
}
date
content
uri
}
}
}
}
}
}Breaking into Fragments
The query is now getting us all the information we need, but it’s starting to get a bit long.
We can use a feature of GraphQL called Fragments to break this into smaller pieces.
I’ve broken the query into several Fragments:
query GetNodeByUri($uri: String!) {
nodeByUri(uri: $uri) {
__typename
...ContentType
}
}
fragment ContentType on ContentType {
name
uri
isFrontPage
contentNodes {
nodes {
...Post
}
}
}
fragment Post on Post {
__typename
id
date
uri
content
title
...Author
}
fragment Author on NodeWithAuthor {
author {
node {
name
avatar {
url
}
}
}
}
Fragments allow us to break the query into smaller pieces, and the fragments can ultimately be coupled with their components that need the data being asked for in the fragment.
Here, I’ve created 3 named fragments:
- ContentType
- Post
- Author
And then we’ve reduced the nodeByUri field to only ask for 2 fields:
- __typename
- uri
The primary responsibility of the nodeByUri field is to get the node and return it to us with the __typename of the node.
The ContentType fragment is now responsible for declaring what is important if the node is of the ContentType type.
The responsibility of this Fragment is to get some details about the type, then get the content nodes (posts) associated with it. It’s not concerned with the details of the post, though, so that becomes another fragment.
The Post fragment defines the fields needed to render each post, then uses one last Author fragment to get the details of the post author.
We can execute this query, and get all the data we need to re-create the homepage!! (sidebar widgets not included)
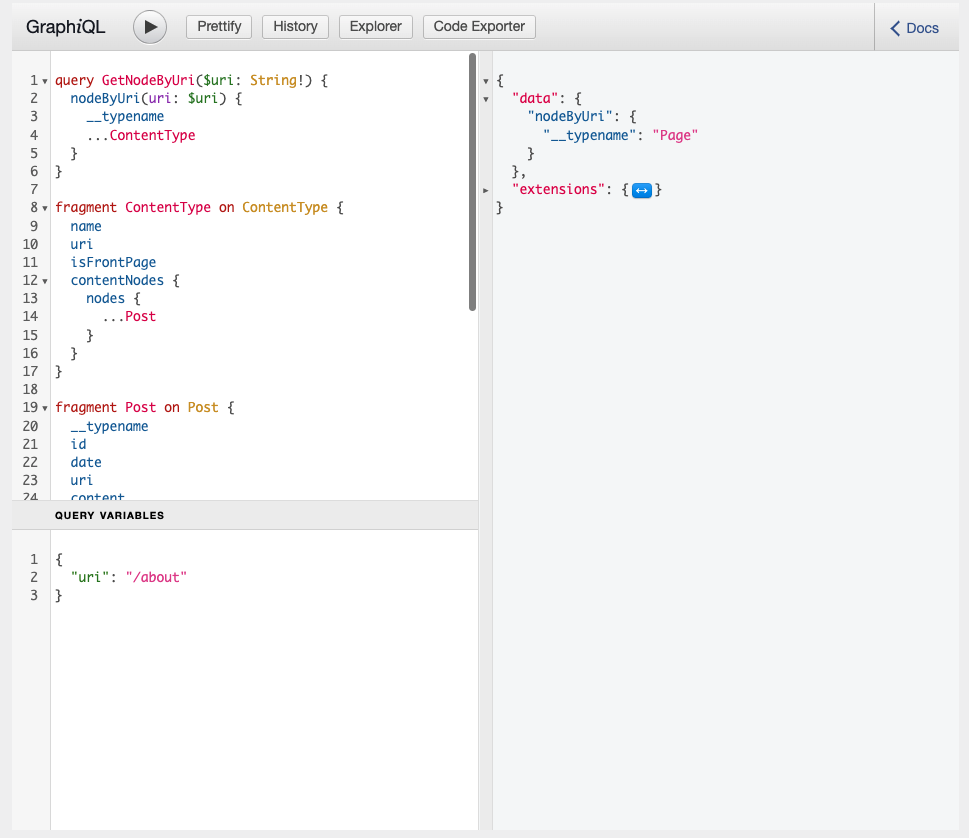
Querying a Page
Now, we can expand our query to account for different types.
If we enter the /about path into our “uri” variable, and execute the same query, we will get this payload:
{
"data": {
"nodeByUri": {
"__typename": "Page"
}
}
}
We’re only getting the __typename field in response, because we’ve told GraphQL to only return data ...on ContentType and since the node was not of the ContentType type, we’re not getting any data.
Writing the fragment
So now, we can write a fragment to ask for the specific information we need if the type is a Page.
fragment Page on Page {
title
content
commentCount
comments {
nodes {
id
content
date
author {
node {
id
name
... on User {
avatar {
url
}
}
}
}
}
}
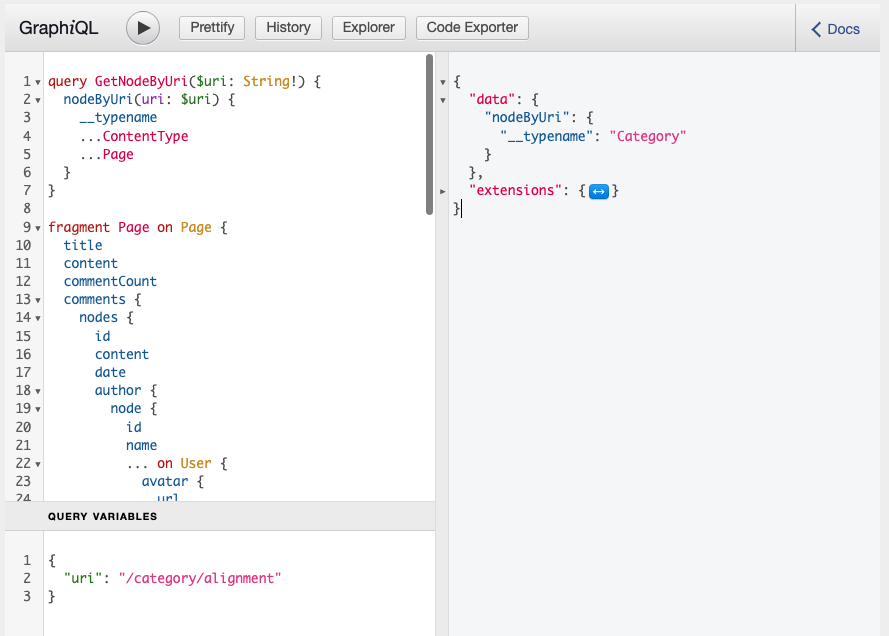
}And we can work that into the `nodeByUri` query like so:
query GetNodeByUri($uri: String!) {
nodeByUri(uri: $uri) {
__typename
...ContentType
...Page
}
}So our full query document becomes (and we could break the comments of the page into fragments as well, too):
query GetNodeByUri($uri: String!) {
nodeByUri(uri: $uri) {
__typename
...ContentType
...Page
}
}
fragment Page on Page {
title
content
commentCount
comments {
nodes {
id
content
date
author {
node {
id
name
... on User {
avatar {
url
}
}
}
}
}
}
}
fragment ContentType on ContentType {
name
uri
isFrontPage
contentNodes {
nodes {
...Post
}
}
}
fragment Post on Post {
__typename
id
date
uri
content
title
...Author
}
fragment Author on NodeWithAuthor {
author {
node {
name
avatar {
url
}
}
}
}
And when we execute the query for the “/about” page now, we are getting enough information again, to reproduce the page that WordPress renders:
{
"data": {
"nodeByUri": {
"__typename": "Page",
"title": "About",
"content": "WP Test is a fantastically exhaustive set of test data to measure the integrity of your plugins and themes.
\nThe foundation of these tests are derived from WordPress’ Theme Unit Test Codex data. It’s paired with lessons learned from over three years of theme and plugin support, and baffling corner cases, to create a potent cocktail of simulated, quirky user content.
\nThe word “comprehensive” was purposely left off this description. It’s not. There will always be something new squarely scenario to test. That’s where you come in. Let us know of a test we’re not covering. We’d love to squash it.
\nLet’s make WordPress testing easier and resilient together.
\n",
"commentCount": 1,
"comments": {
"nodes": [
{
"id": "Y29tbWVudDo1NjUy",
"content": "Test comment
\n",
"date": "2021-12-22 12:07:54",
"author": {
"node": {
"id": "dXNlcjoy",
"name": "wpgraphqldemo",
"avatar": {
"url": "https://secure.gravatar.com/avatar/94bf4ea789246f76c48bcf8509bcf01e?s=96&d=mm&r=g"
}
}
}
}
]
}
}
}
}Querying a Category Archive
We’ve looked at querying the home page and a regular page, so now let’s look at querying a category archive page.
If we navigate to https://demo.wpgraphql.com/category/alignment/, we’ll see that it’s the archive page for the “Alignment” category. It displays posts of the category.
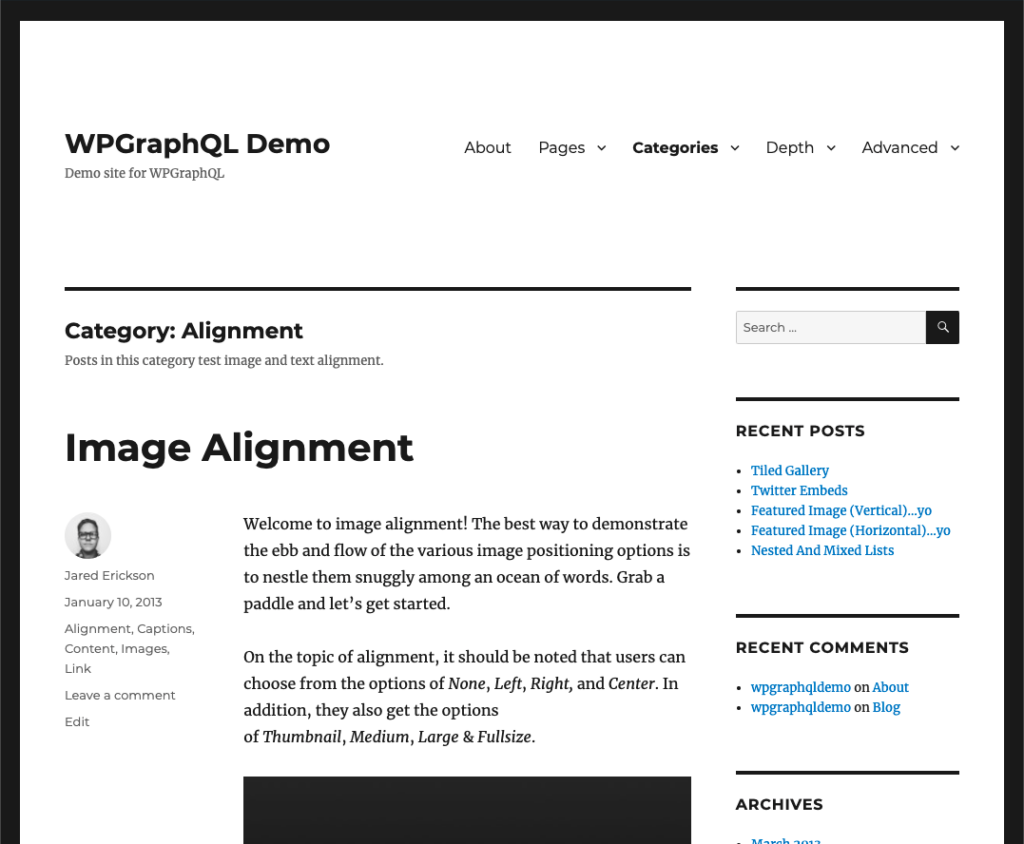
If we add “/category/alignment” as our variable input to the query, we’ll now get the following response:
{
"data": {
"nodeByUri": {
"__typename": "Category"
}
}
}
So now we can write our fragment for what data we want returned when the response type is “Category”:
Looking at the template we want to re-create, we know we need to ask for:
- Category Name
- Category Description
- Posts of that category
- title
- content
- author
- name
- avatar url
- categories
- name
- uri
So we can write a fragment like so:
fragment Category on Category {
name
description
posts {
nodes {
id
title
content
author {
node {
name
avatar {
url
}
}
}
categories {
nodes {
name
uri
}
}
}
}
}And now our full query document looks like so:
query GetNodeByUri($uri: String!) {
nodeByUri(uri: $uri) {
__typename
...ContentType
...Page
...Category
}
}
fragment Category on Category {
name
description
posts {
nodes {
id
title
content
author {
node {
name
avatar {
url
}
}
}
categories {
nodes {
name
uri
}
}
}
}
}
fragment Page on Page {
title
content
commentCount
comments {
nodes {
id
content
date
author {
node {
id
name
... on User {
avatar {
url
}
}
}
}
}
}
}
fragment ContentType on ContentType {
name
uri
isFrontPage
contentNodes {
nodes {
...Post
}
}
}
fragment Post on Post {
__typename
id
date
uri
content
title
...Author
}
fragment Author on NodeWithAuthor {
author {
node {
name
avatar {
url
}
}
}
}And when I execute the query for the category, I get all the data I need to create the category archive page.
Amazing!
Any Type that can be returned by the nodeByUri field can be turned into a fragment, which can then be coupled with the Component that will render the data.